Trascrivere e rendere analizzabili elettronicamente le scritture a mano in Europa. Queste sono le funzioni della piattaforma Transkribus, una delle iniziative portate avanti dal progetto READ, finanziato dal programma European Union’s Horizon 2020 Research and Innovation.
La trascrizione dei Quaderni del carcere di Gramsci
Un esempio concreto di come opera Transkribus è la trascrizione dei Quaderni del carcere di Gramsci, sperimentata dal direttore del Gramsci centre for the Humanities, Massimo Mastrogregori.
Direttore, come è arrivato a scoprire la piattaforma Transkribus e i suoi servizi?
Ho scoperto la piattaforma Transkribus facendo delle ricerche in Rete, mentre cercavo un programma simile al tipo Ocr (riconoscimento ottico dei caratteri), ma utilizzabile per la trascrizione di manoscritti. Lo scopo iniziale di questa ricerca era quello di far acquisire a un computer il mio archivio manoscritto, che negli ultimi anni ha raggiunto una mole considerevole diventando difficile da gestire. Ma ho pensato che una simile piattaforma potesse essere utilizzata anche per perseguire uno scopo meno “pratico”.
Quali risultati ha ottenuto applicando gli strumenti di trascrizione e analisi di Transkribus sui Quaderni del carcere di Gramsci?
La prima operazione svolta è stata quella di caricare nella piattaforma le immagini di alcuni quaderni di Gramsci e utilizzare Transkribus per la trascrizione a mano. Questo passaggio è indispensabile, altrimenti il software non apprende il riconoscimento della scrittura: viene segmentato il testo dell’immagine caricata, riga per riga. A ogni riga del testo-immagine corrisponde una riga di testo – trascritto manualmente.
Raggiunta la quantità richiesta di righe trascritte a mano, ho avvisato il team di Transkribus a Innsbruck, che ha prodotto un modello in base al quale ora la piattaforma riconosce la scrittura di Gramsci, con una percentuale di errore, sulla carta, molto bassa.
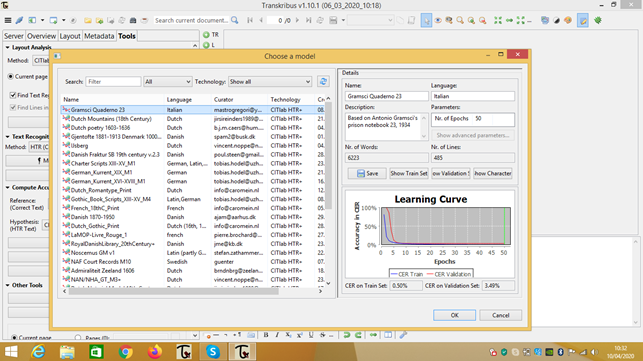
Nel grafico qui in alto si può notare la learning curve: si abbassa fino a diventare piatta. All’inizio dell’addestramento – che il programma compie confrontando i dati immessi e le immagini del testo – c’è il 100% di errore, alla fine il 3% circa. Grazie al modello della scrittura di Gramsci creato a Innsbruck, Transkribus è ora in grado di compiere da solo la trascrizione.
Così ho ottenuto la trascrizione automatica dei quaderni gramsciani, primi testi di un autore italiano ad essere trattati dal programma. Anche se il margine di errore finale è risultato basso, ci vorranno alcune settimane di lavoro per correggere quanto elaborato. Il lavoro, ovviamente, non finisce qui. Il progetto di ricerca del Gramsci centre di San Marino riguarda due questioni collegate tra loro: come analizzare anche “automaticamente” i Quaderni; come produrre un’innovativa edizione elettronica del testo gramsciano, che non sia una semplice riproduzione dei testi.

Intervista a Daniele Fusi, filologo digitale
Abbiamo interpellato Daniele Fusi, ricercatore in Digital Textual Scholarship presso il Venice University Centre for Digital and Public Humanities (VeDPH). Quella che segue è la prima di tre parti dell’intervista che il dottor Fusi ci ha gentilmente concesso riguardo la sua esperienza di filologo digitale; la frontiera attuale dell’analisi elettronica dei testi e le opportunità offerte dalla piattaforma Transkribus.
Dottor Fusi, come studioso classicista con una lunga esperienza nell’analisi elettronica dei testi, quali sono i principali campi in cui ha operato?
Benché la mia formazione sia di classicista, specialmente nei campi della linguistica storica e metrica classici, unisco alla mia attività di ricercatore quella di consulente informatico ideando e sviluppando sistemi software per istituzioni accademiche e non, e aziende private.
Quanto soprattutto emerge dalla mia varia attività in questo ambito è una serie di convergenze sempre più evidenti verso modelli e architetture che tendono a una più netta strutturazione del contenuto digitale e alla sua crescente esigenza di espansione e interconnessione.
Ad esempio, esperienze e riflessioni nel campo delle edizioni digitali in vari ambiti (letterario, epigrafico, antico, moderno…) hanno condotto a proporre dei nuovi strumenti per semplificare la creazione di contenuti complessi, quali richiedono ormai l’intrinseca natura di molti documenti o la sistematica analisi linguistica effettuata da sistemi NLP. L’idea generale qui richiede l’abbandono di visioni cui ci ha abituato la tradizione della stampa, per abbracciare un vero e proprio paradigma digitale, modellando i dati in modo il più possibile indipendente da condizionamenti mentali o tecnologici. Uno degli strumenti creato per favorire questa visione è un sistema di editing (Cadmus) che opera in un’architettura aperta ed espandibile, dove dati indifferentemente testuali, metatestuali o non testuali trovano una comune collocazione, pur consentendo di generare output più tradizionali come ad esempio XML-TEI.
Le edizioni digitali si pongono peraltro ormai come vero e proprio strumento, sicché su di esse possono essere basati sistemi capaci di produrre nuovi dati. Ad esempio, ho utilizzato corpora digitali per un sistema di analisi metrica (Chiron) aperto a qualsiasi lingua e tradizione poetica, ottenendo un’enorme mole di dati di grande dettaglio e interesse. Questo a sua volta comporta nuove sfide: quando 90mila versi analizzati conducono a 80 milioni di dati linguistici e metrici, risulta necessario adottare tecniche di analisi adatte a questa scala, come ad esempio quelle di Machine Learning, capaci di evidenziare pattern linguistici, metrici e letterari estremamente fecondi per la ricerca, e di mettere alla prova i propri modelli esplicativi con la falsificazione delle loro previsioni.
Peraltro, a loro volta simili strumenti hanno ricadute sui corpora da cui traggono il materiale di analisi: l’enorme dettaglio di dati prosodici e metrici prodotta dal sistema può infatti a sua volta tornare ai corpora sotto forma di annotazione, e sistemi di ricerca opportunamente confezionati possono trarne vantaggio, offrendo nuove possibilità di interrogazione: di qui ad esempio un semplice sistema DBT (Pythia) basato su un livello di astrazione più alto e creato anche per trattare i dati prodotti dal mio sistema.
Accanto a risorse nativamente concepite come digitali, esiste poi il problema di recuperare e rimodellare un enorme patrimonio di corpora e lavoro di studiosi spesso ancora affidato a supporti cartacei, o al loro equivalente digitalizzato. È questo un campo in cui opero per edizioni critiche, dizionari, corpora, e documenti archivistici, realizzando sistemi di conversione e rimodellazione (Proteus) che al di là del loro fine pratico possono insegnare qualcosa sulla differenza che passa fra un testo digitalizzato e uno digitale.
Continua…
Un commento su “Transkribus e le frontiere dell’analisi elettronica dei testi: l’esempio dei Quaderni del carcere”